


通信世界网消息(CWW)“一个只有8G显存需求的小实验,为什么要独占整张高端GPU卡?”
“为什么算法工程师调一次参数,还要排队抢显卡?”
在算力成为企业核心生产力的大背景下,GPU资源紧张、采购昂贵、利用率不均衡等问题正成为AI落地的最大掣肘。
针对这些行业痛点,优刻得正式发布新一代GPU虚拟化技术,通过显存与算力的双维度切分能力,将单张GPU的资源拆分为多个独立的虚拟算力单元,切分粒度最小可精确至10%。该能力使单卡可同时承载多个AI工作负载,在推理服务、模型开发、科研教学等场景显著提升资源利用率。
依托轻量级用户态截获与API调度机制,优刻得GPU虚拟化技术实现了显存、CUDA核心资源的可控分配与强隔离,避免传统共享模式下的“邻居干扰”与显存溢出导致整卡崩溃的问题。官方实测显示,虚拟化带来的性能损耗可控制在1%–3%,接近原生GPU的使用体验。
随着华为Flex:ai等技术推动算力切分逐渐成为行业趋势,优刻得此次发布的GPU虚拟化能力在芯片适配层面进一步拓展,已覆盖NVIDIA、昇腾、寒武纪、沐曦等更多架构。

图片由AI生成
创新技术路线:把GPU变成真正“可共享”的资源池
不同于传统的MPS(多进程服务)或简单的分时复用方式,优刻得GPU虚拟化技术采用API劫持+用户态轻量截获的技术路线,在GPU与上层应用之间构建一层智能、轻量、可控的虚拟化管理层,让显卡资源的分配更精确、更稳定:
显存与算力的双重精细化调度,让任务之间各行其道
传统GPU共享方式中,一个任务显存泄露可能导致整卡服务一起“陪跑”。优刻得通过设置显存硬上限和算力百分比分配,自上而下实现真正意义上的资源隔离,任务各自运行互不干扰。
性能损耗极低,迁移成本几乎为零
虚拟化层采用轻量级用户态截获技术,不做重度改写、不增加冗余逻辑,GPU指令几乎以“直通”方式完成。同时,开发者在迁移时也无需修改代码或重建镜像。
原生支持异构与国产化,算力调度更加灵活开放
在原生Kubernetes调度能力基础上进一步扩展,实现在NVIDIA、昇腾、寒武纪、沐曦等芯片间的统一管理,并支持binpack、spread等多种调度策略。
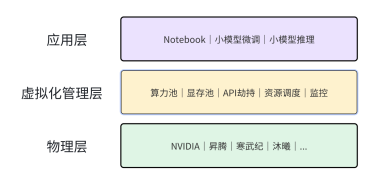
通过上述创新技术路线,优刻得GPU虚拟化技术能够覆盖更广泛的算力环境,为政企、科研、制造等行业提供灵活可控的算力基础设施。
应用场景持续扩展,助力多行业客户实现降本增效
除了高校教学与企业研发场景外,优刻得GPU虚拟化技术正在多个AI落地场景中创造价值。
在小参数量大模型(LLM)推理服务中,如7B、13B模型,其显存占用相对固定,但计算负载往往达不到整卡算力,造成显著资源浪费。通过虚拟化技术,一张GPU可同时部署2–4个推理副本,显著提升单卡并发能力(QPS),大幅降低推理成本。
在高校科研、教学实验与企业研发场景中,Notebook或调试任务往往只需少量显存。借助优刻得GPU虚拟化,一张80GB显存的显卡可切分为8–10个小实例,实现单设备的十倍资源复用,显著缓解研发排队与设备不足的问题。
通过上述能力,优刻得正推动算力资源向精细化管理转变,让AI研发、推理与应用部署更加轻量、高效、可控,为各行业释放更大算力价值。
