

通信世界网消息(CWW)12月5日,摩尔线程智能科技(北京)股份有限公司(以下简称“摩尔线程”)正式在上海证券交易所科创板挂牌上市。作为A股市场名副其实的“国产GPU第一股”,开盘报650元/股,较发行价114.28元/股上涨468.78%,总市值突破3000亿元,无论从估值、募资规模还是市场关注度来看,都远超市场预期。

从提交申请到成功过会,摩尔线程的科创板IPO之旅堪称“高速”。之所以能获得监管与资本的双重认可成功上市,其背后是清晰且稀缺的技术路径、扎实的产品迭代与生态构建,并且精准把握住了AI新时代的算力脉搏。
五年逆袭:从初创公司到科创板新贵
摩尔线程的故事始于2020年。彼时,全球GPU市场被英伟达、AMD垄断,仅英伟达在全球GPU市场中的份额即达到90%—95%。在此背景下,摩尔线程创始人张建中,这位曾担任英伟达全球副总裁、大中华区总经理的行业老兵,带领一支深耕GPU领域多年的团队,在北京悄然成立了这家以“全功能GPU”为使命的公司。

成立之初,企业就面临研发投入高、生态构建难的双重挑战。招股书显示,2022年至2024年,公司研发费用分别高达11.2亿元、13.3亿元、13.6亿元,连续三年远超同期营收。但高强度投入换来了技术突破,凭借深厚积淀,摩尔线程的发展节奏快得令人瞩目。
2021年,实现多轮大额融资为研发注入资金,团队迅速扩张。
2022年,推出首款GPU芯片“苏堤”,秋季迭代出“春晓”和消费级显卡MTT S80,成为国内首款支持Windows DirectX 12的显卡。
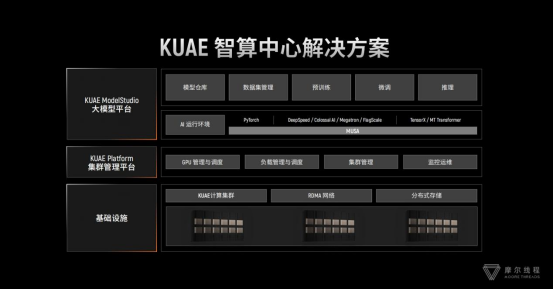
2023年,其推出的“夸娥”(KUAE)智算集群成为国内首个基于全功能GPU的大规模智算解决方案,服务于大模型训练。
2024年,第四代“平湖”架构性能接近国际先进水平,支持千亿参数大模型训练。同年,夸娥(KUAE)智算集群解决方案实现重大升级,从千卡扩展至万卡规模,成为首个国产GPU万卡集群。
摩尔线程夸娥(KUAE)智算集群
五年间,摩尔线程完成四代GPU架构迭代,从“苏堤”到“平湖”,产品性能持续跃升,第四代“平湖”架构新增FP8精度支持,可支撑面向DeepSeek类前沿大模型预训练的万卡集群智算中心解决方案产品。
产品矩阵的完善推动营收增长。招股书显示,2022年至2024年,公司营业收入由0.46亿元增长至4.38亿元,复合增长率为208.44%。2025年上半年更是实现7.02亿元营收,超过前三年总和。伴随AI智算业务爆发,业务结构也进而优化,2024年该业务收入占比从0飙升至77.6%,2025年上半年进一步提升至95%,且毛利率维持在69%以上的高位,成为公司的核心盈利支柱。
鉴于此前高研发投入,公司目前仍处于亏损状态。2025年上半年归母净利润为-2.71亿元,但亏损幅度较前期已显著收窄。公告披露,公司预计最早于2027年实现盈利。
资本的持续加持成为重要助推力。上市前,摩尔线程已完成多轮融资,股东阵容涵盖中国移动、红杉资本、字节跳动、腾讯等产业资本与头部VC。
值得一提的是,摩尔线程实现了2022年以来审核最快的科创板IPO,受理到过会仅88天,刷新科创板“硬科技”企业审核速度纪录。这背后是科创板“1+6”政策体系对未盈利“硬科技”企业的上市支持,也印证了监管层对GPU国产替代的战略认可。
核心优势构筑护城河:成就国产GPU第一股
摩尔线程能够快速过会并获得超高估值,其核心竞争力在于构建了多重难以复制的护城河。
其一,技术路径的稀缺性与前瞻性。在技术路线上,摩尔线程选择了“全功能GPU”路线。所谓“全功能GPU”,是一类兼顾通用计算、AI加速计算与图形计算的综合型处理器。其与去掉图形渲染模块、专注于AI加速计算的GPGPU和应用于特定领域的DSA/ASIC芯片分属AI芯片领域的不同技术路径。
相较于其他两种,全功能GPU兼顾通用计算、AI加速计算与图形计算的综合型处理器,具有DSA芯片的效率优势,又保持着GPU固有的灵活性与扩展性,技术门槛最高。
在全球范围内,英伟达作为绝对霸主,已经走通了全功能GPU从底层技术到生态再到商业化的闭环。以此为鉴,加之“全功能GPU”在通用性、灵活性上比其他技术有着更大优势,具有唯一性,可以避免陷入单一领域的竞争,摩尔线程选择了这样一条技术路径。
自2020年成立以来,摩尔线程已构建起从芯片到集群的智算完整产品线,也是国内少数在B端和C端均有布局的GPU创新企业,形成了覆盖多场景的业务架构。
其二,自主研发的MUSA生态体系。正如芯片价值一半在硬件,一半在生态,GPU也同理。摩尔线程自主研发的MUSA统一系统架构是其生态基石。该架构可以完整兼容CUDA,又可以独立发展自己的MUSA生态,开发者可以快速地将CUDA应用迁移到MUSA上,实现快速无缝迁移。同时,公司提供完整的MUSA软件栈与开发工具,积极构建自主生态。截至2025年6月,已获得授权专利514项,授权专利数量在国内GPU企业中排名领先。
其三,超快的技术与产品迭代能力。AI时代,算力需求呈指数级迭代。摩尔线程展现了国内罕见的“年更”节奏,保持每年推出一颗新芯片。从消费级显卡更新以流畅运行《黑神话:悟空》等3A大作,到“夸娥”智算集群从千卡扩展到万卡级能力,其工程化与系统级创新能力持续突破。
其四,成熟的“B+C”双端布局。摩尔线程作为国内极少数同时在企业级数据中心、智算市场和消费级显卡、云电脑市场均有深度布局的GPU厂商之一。这种布局不仅分散了市场风险,更使其技术能在最苛刻的图形场景和最高负荷的计算场景中同时得到锤炼,形成良性互动。
适逢其时:激活国产GPU生态链与竞争格局
摩尔线程的IPO时间节点,恰逢全球AI算力需求爆发与国产替代进程提速的交汇点。
一方面,全球AI算力需求大爆发。人工智能的快速发展催生了海量算力需求,国内智算中心建设如火如荼,高端算力短缺已经成为制约AI产业发展的关键瓶颈。而摩尔线程的产品已实现部分场景替代,其智算集群在政务云、行业大模型训练等场景的落地,有效缓解了算力供给压力。
另一方面,国产算力自主替代的紧迫性日益凸显。国际环境复杂多变,高端GPU供应链安全成为国家战略关注的焦点。摩尔线程在2023年被美国列入“实体清单”,虽对供应链造成短期压力,但也从侧面印证了其技术实力,并进一步强化了国内市场对其作为国产替代核心选项的期待。
在政策强力支持与国家算力体系建设的大背景下,国产GPU企业迎来了黄金窗口期。根据弗若斯特沙利文预测,到2029年,中国的AI芯片市场规模将从2024年的1425.37亿元激增至13367.92亿元。从细分市场上看,GPU的市场增长速度最快,其市场份额预计将从2024年的69.9%上升至2029年的77.3%。
综合来看,摩尔线程的成功上市,为国产高端GPU研发注入了“强心剂”。根据招股书,其上市募集资金将主要用于新一代AI训推一体芯片、图形芯片及AI SoC芯片的研发,这将极大加速其技术追赶上国际领先水平的进程。
更为重要的是,作为“第一股”,它树立了一个资本市场与技术产业联动标杆,有望吸引更多资金和人才涌入国产GPU赛道,提振整个产业链的信心。
此外,不可忽略的是,摩尔线程的上市,无疑将国产GPU的竞争推向了新阶段。纵观国内赛道,“国产GPU四小龙”中的壁仞科技、燧原科技、沐曦股份亦在快步前行。
展望未来,国产GPU行业将进入“市场验证”与“技术攻坚”并行的深水区。市场不再仅仅为“国产”概念买单,而是会严格审视产品的实际性能、稳定性、能耗比和生态支持。
长久来看,行业整合或许不可避免,但拥有核心技术、清晰路径和商业落地能力的企业将最终胜出。
