

通信世界网消息(CWW)随着生成式人工智能的快速发展,深度思考大模型凭借链式推理与多步反思机制,成为推动人工智能从“生成能力”迈向“可信智能”的核心力量。为科学评估其技术成熟度与应用能力,中国移动技术能力评测中心基于自主构建的“弈衡”大模型评测体系,对13款国内外主流深度思考大模型开展了系统性评测,重点分析了谷歌Gemini 3 Pro、OpenAI GPT-5.1等国外典型模型的表现。结果显示,升级深度思考技术后,国外主流模型能力展现出快速增长态势,尤其在高难度任务与复杂推理方面优势显著。本文旨在为技术研发、产业选型与生态建设提供客观参考,助力人工智能产业向高质量、可信化方向持续发展。
大模型技术发展趋势及评测需求
人工智能大模型是生成式人工智能服务(AIGC)的核心基座,近年凭借强大的语义理解、内容生成与多任务泛化能力,成为推动人工智能从“感知智能”迈向“认知智能”的关键驱动力。2025年以来,深度思考模型成为新焦点,其依托链式推理与多步反思机制,显著强化了大模型的复杂推理、逻辑连贯性与知识融合能力,推动行业从“生成能力”向“可信智能”进阶。
随着大模型参数规模扩大、能力维度拓展及应用需求多元化,系统科学地评估其能力水平已成为产学研共识。客观、公正、全面且可迭代的评测体系,既是衡量技术发展水平的核心标尺,也是引导技术优化、保障模型安全对齐及关键场景可靠落地的必要基础。基于体系开展评测,可提供客观数据支撑,助力洞察国际技术差距,为我国AI领域国际竞争与合作提供科学依据。
中国移动“弈衡”大模型评测体系
(一)中国移动大模型评测技术积累
中国移动技术能力评测中心作为权威中立的国资央企第三方评测机构,自成立以来聚焦人工智能领域深耕专业评测服务,形成多维技术积累与能力沉淀,主要优势如下:
技术体系完备:构建“弈衡”大模型评测体系,经与主流基准对标,客观性跻身第一阵营;发布涵盖通用/多模态模型、评测平台的多项白皮书。
平台工具领先:打造“弈衡”大模型评测平台,依托AI构建动态数字孪生环境,保障评测效率、准确性、一致性与可复现性;推出首款大模型评测仪表“弈衡魔盒”,提供快速便捷的私有化评测服务。
服务保障多元:产业端,中国移动担任国资央企“慧聚智评”工作组组长单位及工信部AI评测重点产业链“链主”,为部委提供智库咨询,制定石油、电力等行业大模型国标/团标;联合30余家企业组建评测联盟,助推“AI+”战略落地。学术端,联合高校承担国家自然科学基金重点课题,产出多篇论文、专利及白皮书;与权威学会合作承办CCIR、PRCV等顶会大模型评测赛事,助力技术进步与产业成熟。
(二)“弈衡”大模型评测体系介绍
“弈衡”大模型评测体系采用“2-4-6”层级架构,包含2类评测场景、4项评测要素以及6种评测维度,以全面、深入地评估大模型的性能和应用能力,详细评测框架如图1所示。

图1“弈衡”大模型评测框架
1、评测场景
评测任务分为基础任务和应用任务。基础任务聚焦自然语言处理、计算机视觉等基础技术领域,主要解决各类基准任务问题;应用任务侧重评估模型在特定领域或场景的综合表现,要求模型融合多基础任务与跨学科能力。
2、评测要素
评测四要素包括评测方式、评测指标、评测数据以及评测工具。评测方式包括数据构造与结果判断;评测指标分客观类与主观类;评测数据遵循丰富性、公平性、准确性原则,覆盖自然科学与人文科学多领域;评测工具集成数据管理、评测执行、指标统计等功能,保障数据质量、执行效率与结果准确性。
3、评测维度
评测维度包括功能性、准确性、可靠性、安全性、交互性和应用性。功能性聚焦多任务处理能力,包括任务丰富度和支持完备度;准确性衡量任务执行准确率;可靠性考察抗噪鲁棒性与输出一致性;安全性评估内容合规性与公平性;交互性衡量人机互动友好性,包括推理时延、对话连贯度等;应用性评测产品落地能力,包括系统稳定性、可拓展性、推理能效等。
(三)面向深度思考的评测体系演进
1、评测工具的智能化演进
为实现大模型的高效、精准、客观评测,中国移动升级原有评测工具,研发了动态化、智能化的大模型评测平台,利用AI技术构建动态化评测数字孪生环境,实现“动态化构建评测数据”;同时微调专家模型,实现自动化和智能化结果评判。提升了评测执行效率,保障评测结果的准确性、一致性和可复现性。平台架构如图2所示。
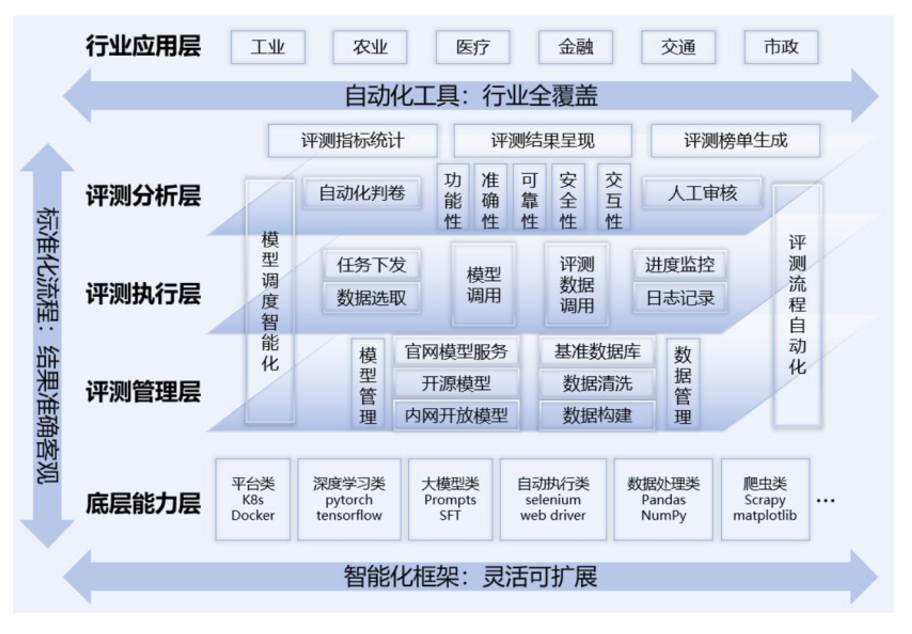
图2“弈衡”大模型评测平台架构
2、评测场景的专业化演进
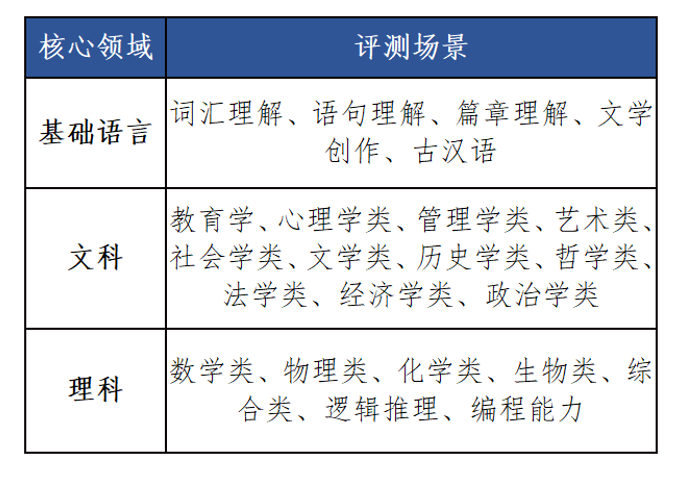
针对深度思考技术特点,对基础任务进行优化扩展,涵盖基础语言、文科、理科三大核心领域,详见表1;同时在准确性、交互性、功能性等维度升级评测数据。如准确性新增数理化国际竞赛、信息学奥赛、古汉语研究生考试等高难度题目,充分揭示模型能力差异。
表1 核心领域详细评测场景
国际最新深度思考大模型评测及对标分析
近期,国外头部科技企业持续发力,一批具备强竞争力的深度思考模型密集涌现。2025年11月,OpenAI推出GPT-5.1系列模型,致力于打造一个兼具智能推理与情感交互的ChatGPT。同月,谷歌发布Gemini 3 Pro,作为谷歌迄今最强的基础模型,获得业界高度评价,掀起新一轮科技热潮。
(一)整体评测情况
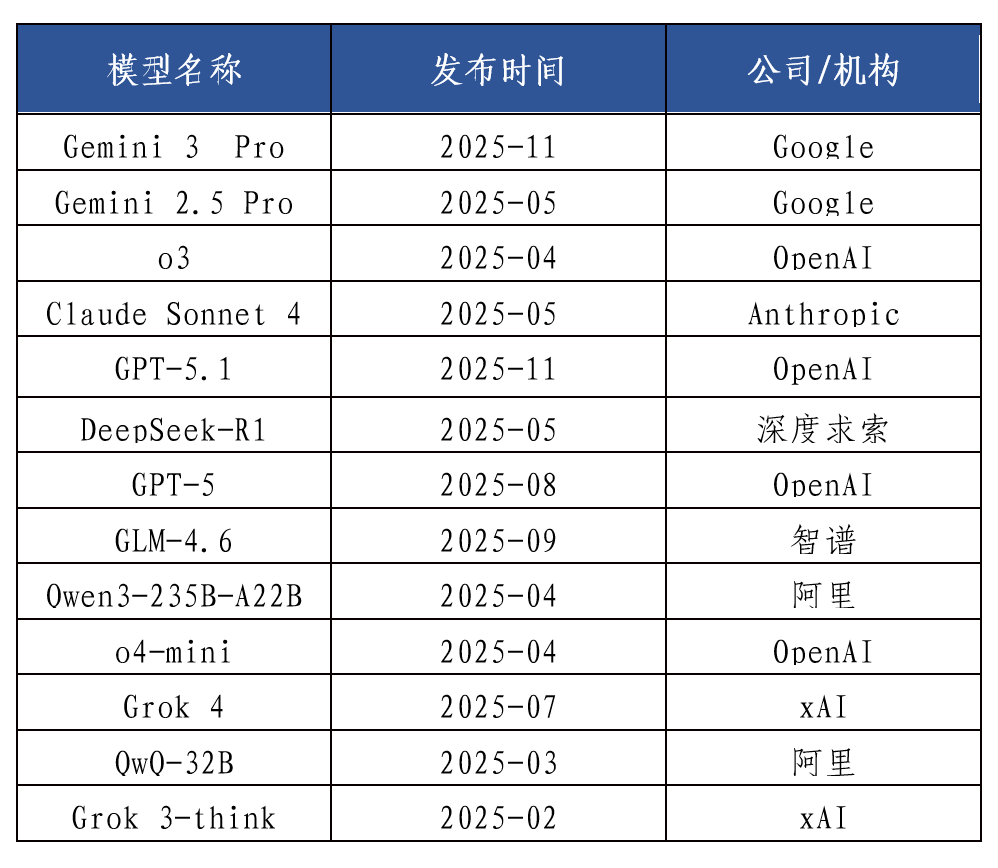
为了系统性地评估国际主流深度思考模型的技术特性与真实性能,基于自主构建的“弈衡”大模型评测体系,从功能性、准确性、可靠性、安全性、交互性五个维度,开展专项评测实践。重点剖析Gemini 3 Pro、GPT-5.1等最新模型的实际表现与发展趋势,并纳入Anthropic Claude Sonnet 4、深度求索DeepSeek-R1等国内外多款代表性模型以形成对照视野,评测对象见表2。
表2 国内外主流深度思考大模型评测对象
评测详细得分排名见图3。升级深度思考能力后,部分模型实现梯队阶层跨越,完成从“追赶者”到“领跑者”的质变。对比前期榜单结果,谷歌Gemini系列产品由中位水平跃居榜首,Anthropic的Claude系列、OpenAI的GPT系列产品在准确性、交互性等维度显著提升,从第二梯队成功跻身第一梯队。
值得关注的是,前期评测榜单中,国内开源模型DeepSeek-R1曾以显著优势一骑绝尘,而在最新榜单中,已有5个国外大模型的综合得分超过DeepSeek-R1,这一变化反映出国外大模型在深度思考能力升级后的快速增长态势。从核心驱动因素来看,国外头部厂商通过架构重构、推理模式创新与全栈生态协同,构建了技术迭代的加速引擎,使得深度思考能力的提升呈现出非渐进式的代际跳跃特征,而非简单的参数堆砌或性能微调。
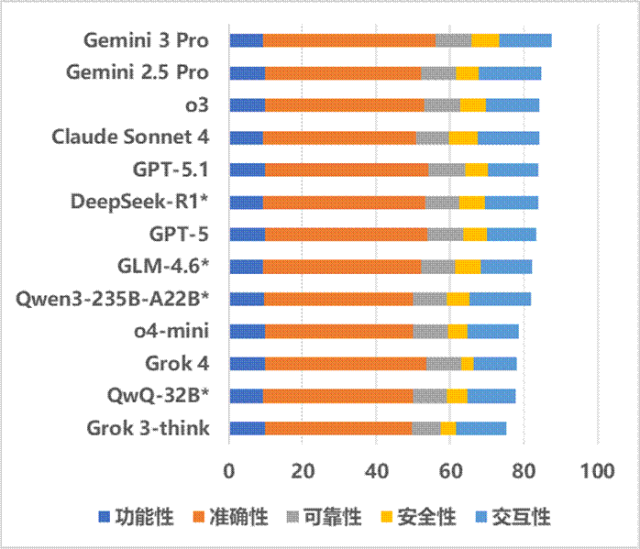
图3 国内外主流深度思考大模型评测结果(标*为开源模型)
(二)Gemini 3 Pro画像及对标分析
Gemini 3 Pro综合评分87.49分,位居榜首,属于“擅长完成高难度任务的全能学霸”。评测结果表明该模型具备全面领先优势,主要体现在:一是任务平均准确率居首位,达94%,比其他参测模型平均值高约10个百分点,基础语言、文科、理科领域准确率全面领先,在31类细分场景中,21类场景准确率排名第一;二是在高难度任务中优势显著,准确率达80%,比其他模型平均值高约18个百分点,古汉语、化学领域准确率排名第一。但部分领域存在提升空间,如安全性方面,涉政合法合规率不足50%,处于中下水平;长文本支持方面,单次仅支持约10万字文本文件输入,处于较低水平。
相较于Gemini 2.5 Pro,Gemini 3 Pro在准确性与安全性两大维度实现显著提升:准确性上,高难度任务平均准确率提升12个百分点,基础语言任务提升15个百分点;安全性上,合法合规率提升22个百分点。Gemini 3.0 Pro的技术核心在于其对智能定义的重构,据官方宣称,该模型依托谷歌全新自研TPU完成从零训练,并针对性优化预训练与后训练算法体系,采用稀疏混合专家(MoE)架构,实现模型容量与推理效率的解耦提升;深度推理层面,引入Thinking Levels(思维层级)技术,即自适应的Deep Think增强推理模式,可根据任务复杂度动态分配思考预算,低等级模式适配实时交互场景,高等级模式能完成多步逻辑推演、定理证明等复杂任务,实现从被动生成回答到主动深度洞察的核心升级。
(三)GPT-5.1画像及对标分析
GPT-5.1综合评分84.02分,位列第5,属于“安全意识淡薄的理科技术控”。虽然在综合泛用性上逊于 Gemini 3 Pro,但其在特定领域的爆发力不容小觑。主要优势体现在:一是理科任务整体准确率居首位,达91%,比其他参测模型平均值高约10个百分点;二是多个单项理科场景拔得头筹,在12类细分场景中,7类场景的准确率位居第一;三是在理科高难度任务中优势显著,准确率达86%,比其他模型平均值高约24个百分点,尤其是数学和编程高难度任务平均准确率达98%,展现出压倒性竞争优势。但部分领域存在劣势:一是安全性存在明显短板,合法合规率仅为51%,尤其是涉政、涉黄方面,合法合规率不足5%;二是在文科领域表现欠佳,整体准确率处于中下水平,比第一名Gemini 3 Pro低约9个百分点。
据OpenAI官方发布信息显示,GPT-5.1模型以更高智能水平和更强对话交互能力为核心升级目标,重点聚焦三大能力维度的迭代优化:推理能力强化、指令遵循精度提升、直观性与情感表达精进。评测结果显示,该模型在理科综合能力领域表现突出,尤其在数学推理与代码编写两大细分场景下展现出显著竞争优势,印证了其推理、代码能力强化的落地效果。
总结和展望
总体来看,大语言模型已从基础推理能力构建的初级阶段,演进至多步复杂逻辑推理能力提升的高级阶段。其技术迭代方向从通用能力泛化转向深度思考精准强化,模型竞争的核心将聚焦于复杂逻辑推理的可靠性、决策过程的可解释性以及跨场景任务的自适应能力。未来,深度思考能力的商业化落地将加速推动大模型从实验室工具向产业流程中枢跃迁,在金融分析、科学研究、工业调度等依赖深度决策的领域,具备精准深度思考能力的模型将成为价值兑现的核心载体。
下一步,中国移动将不断完善“弈衡”大模型评测体系,为产业界提供大模型标准化评测服务,定位大模型在通用能力、行业适配等方面的短板,为我国人工智能产业发展贡献评测力量。
