

通信世界网消息(CWW)工信部发布的2023年上半年通信业经济运行情况显示,全国移动互联网流量增速持续提升。移动互联网累计接入流量及增速情况如图1所示,2023年上半年,移动互联网累计流量达1423亿GB,同比增长14.6%,增速较一季度回升0.9个百分点。移动互联网接入月流量及户均流量(DOU)情况如图2所示,截至6月末,移动互联网用户达14.9亿户,比上年末净增3825万户。6月当月户均移动互联网接入流量达到16.78GB/户·月,同比增长12.8%,较上年12月提高0.6GB/户·月。
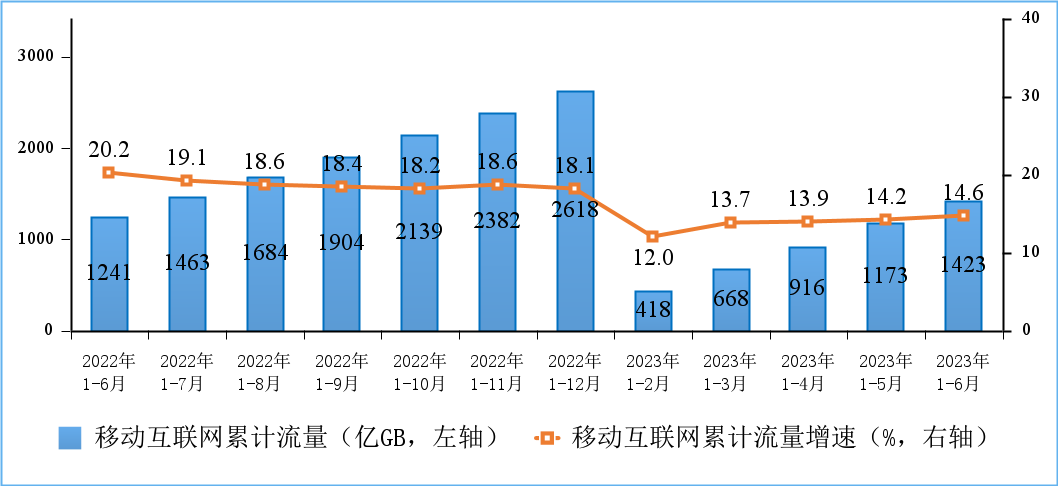
图1 2022年1月—2023年6月我国移动互联网累计接入流量及增速
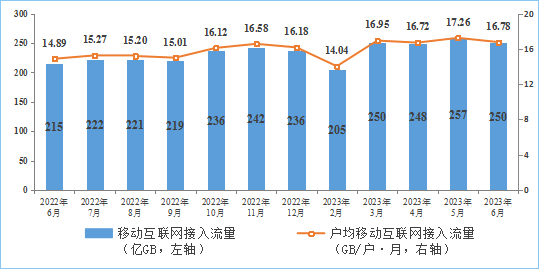
图2 2022年6月—2023年6月我国移动互联网接入月流量及户均流量(DOU)
从收入数据来看,固定互联网宽带业务收入稳步增长。2023年上半年,三大基础电信企业完成互联网宽带业务收入1301亿元,同比增长6.3%,在电信业务收入中占比为15%,较一季度提升0.2个百分点,拉动电信业务收入增长0.9个百分点。移动数据流量业务收入低速增长,上半年,三大基础电信企业完成移动数据流量业务收入3356亿元,同比增长0.2%,在电信业务收入中占比为38.6%,拉动电信业务收入增长0.1个百分点。
从收入数据可以推测流量情况,虽然没有固定互联网流量的数据,但是从收入增长看流量增长不会低于6.3%。考虑到固网“提速降费”因素,推算固定互联网流量增长同比应在10%以上。也就是说,互联网总流量增长同比应在10%以上。
面对如此快速的增长,无论是固定互联网还是移动互联网,在了解整体趋势的同时,如何将内部的流量分互联网流量分布计算模型研究与实践布看得更清楚,以便掌握区域差异、用户行为,从而为扩容、管理提供决策依据就成为急需解决的问题。
本文从运营商视角,研究并探索了一条看清互联网流量分布的路径,旨在研究“区域—区域”间、“用户—区域”间、“用户—业务”间等多维度的互联网流量分布,从而为网络的组织及流量的合理疏导提供依据。
互联网流量分布采集模型
为了了解互联网流量的分布,首先需要获取流量数据。根据目前互联网的网络组织方式,一个大型的网络(如运营商网络)内部会采用分层方式构建,即由一个核心层将各个区域互联起来,区域内部数据交换不经过核心层,与外部交换才经过核心层。一个区域(如省)内可以是分层结构,也可以是不分层结构,目前采用较多的是扁平化不分层结构。
在实际生产过程中,互联网流量流动基本形态如图3所示。其中,每个单元(如IDC、MAN、互联网核心层等)都有独立的AS(自治域)号,但是还有不少在城域网下的IDC没有独立AS。
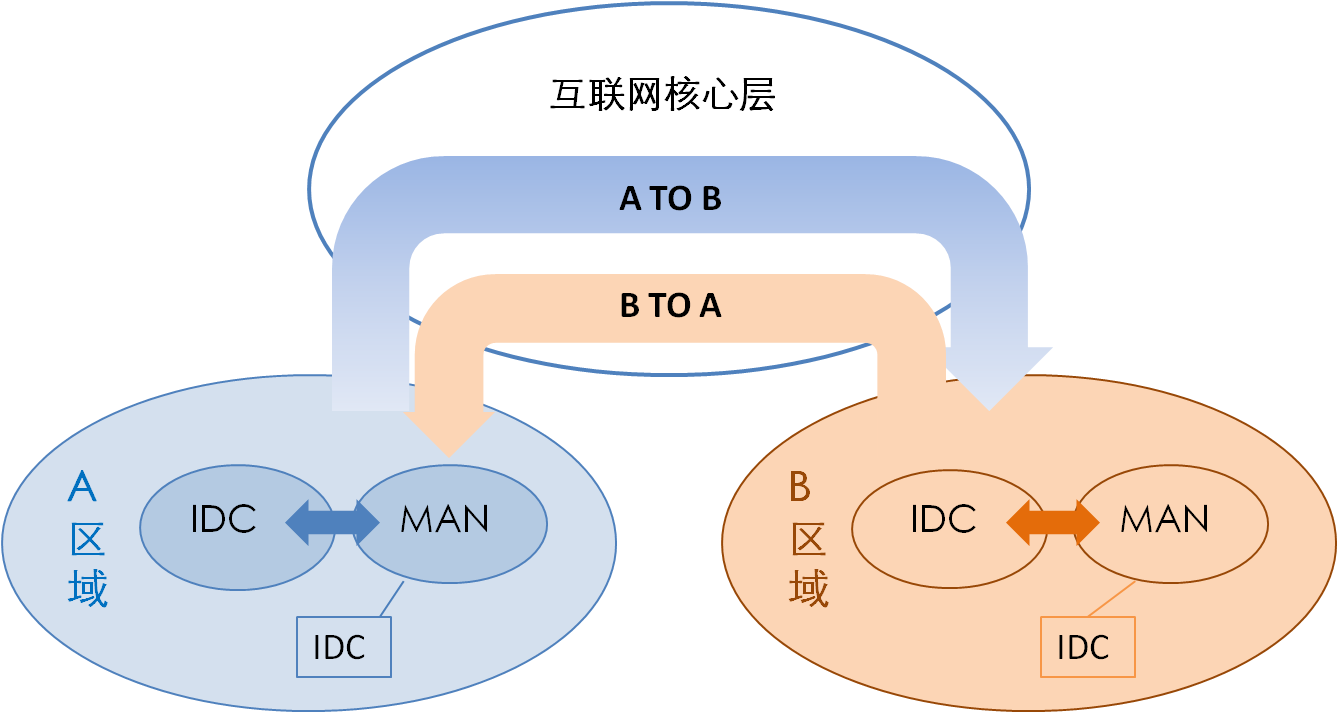
图3 互联网流量流动基本形态
互联网流量的采集模型有骨干核心采集模型、区域核心采集模型、边缘采集模型3种。
骨干核心采集模型
骨干核心采集模型如图4所示,为了掌握区域间的流量分布,即A—B区域交互的流量情况,在图4绿色位置部署采集即可满足。也就是说,如果需要掌握“省—省”之间的流量分布,在核心层周边部署采集即可。
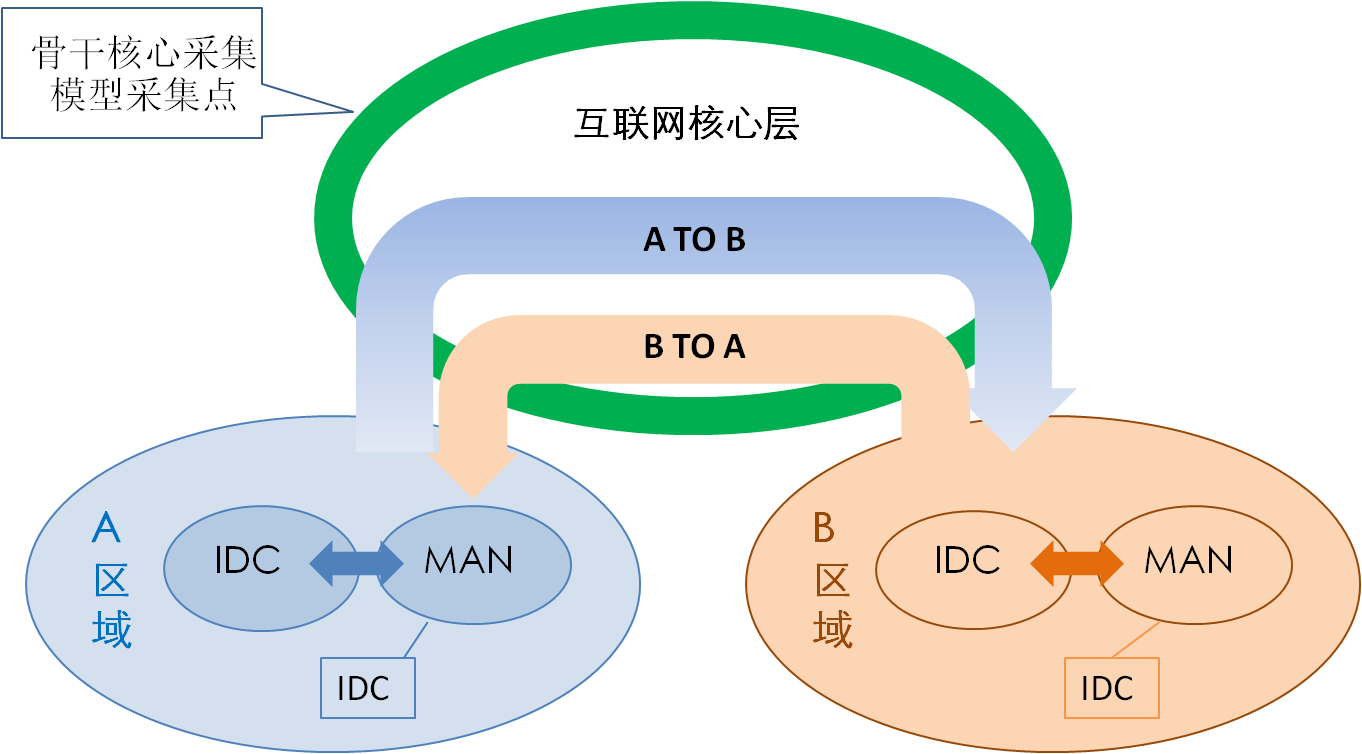
图4 互联网流量骨干核心采集模型
此模型无法采集到区域内部的流量,因此无法准确掌握区域内IDC—MAN不经过核心层的流量情况。
从实际采集量来看,互联网核心层设备数量大约在100台,与区域互联的电路大约在1万条。采集过程通常可由互联网核心层网管系统来综合实现。
区域核心采集模型
区域核心采集模型如图5所示,为了掌握区域内和区域间的流量分布,即除了A—B区域交互的流量情况,还要掌握区域内IDC—MAN不经过核心层的流量情况,则需要在图5绿色位置部署采集。

图5 互联网流量区域核心采集模型
此模型可以采集到扁平化比较彻底的区域内部的全部流量,如果是分层结构,不经过区域核心的下层交互流量无法采集。
从实际采集量看,区域采集设备大约在1000台(各个区域相加),采集电路大约有1万条或是十万条。区域内部采集数量可比照骨干核心采集模型,即区域内部采集设备大约有几十或数百台,区域内互联的电路大约有上千或数万条。
单区域通常可参照互联网核心层,由网管系统综合实现;多区域因各个区域的网管系统不统一,所以需要重新部署采集、存储、计算系统,无法在原有网管系统上叠加,只能由单独的网管系统来实现。
边缘采集模型
边缘采集模型如图6所示,此模型即在离用户端设备最近的一层进行采集,一般是汇聚交换机。此模型能采集到所有流量。

图6 互联网流量边缘采集模型
单区域内部采集量可比照区域核心采集模型,采集设备大约有1000台,采集电路大约在1万或十万条。所有区域采集量,需要在上述基础上增加一个数量级。不过在实际应用中很难有全区域的边缘采集,因为采集量非常大,没有实际的应用场景。通常仅针对部分特定的业务类型,需要在接入层进行全量采集,如直连用户的IDC业务交换机端口,采集接入端口的流量进行计费。
单区域具备由网管系统综合实现的可能,多区域需要由单独的网管系统来实现。
三种模型比较分析
对三种模型从采集量、准确性、复杂度、适用范围进行比较分析如表1所示。
表1 骨干核心、区域核心、边缘3种采集模型对比

综合以上比较分析可以看出,对于单一区域,在准确性要求高的情况下,可采用边缘采集模型;对于多区域场景,兼顾准确性和复杂度,区域核心采集模型较为合理可行。
区域核心采集模型实践要点
流量采集及判断要素
为了实现区域间、用户间、业务间多维度互联网流量分布计算分析,首先需要梳理出涉及分析的关键要素与相应信息的对应关系。
1. 流量采集要素
在数据包层面,根据TCP/IP协议,IP包头中的“五元组”信息(即源地址、目的地址、源端口、目的端口以及协议类型)是关键信息。此数据可通过采样网络Netflow数据获取。同时,AS之间一般使用BGP协议互通,路由表中的AS号信息也是关键信息,此数据可通过读取BGP路由表获取。
在物理端口层面,设备互联端口(包括上联、下联)及流量信息是关键信息。这些信息可以辅助对区域的划分、Netflow数据的完整性及准确性进行校验,通常可采集端口的SNMP数据获取。
2. 流量判断要素
互联网流量的分布判定和识别大致分为三类:针对区域流量分布,主要通过AS、SNMP数据来判定;针对用户流量分布,主要通过AS(有独立AS号用户)及IP(无独立AS号用户)来判定;针对业务流量分布,主要通过AS(可通过AS区分的业务,如IDC业务、移动业务)及IP(如MAN内的IDC业务)来判定。
流量采集和判断方法
为确保流量既完整又不重复,需采集区域核心设备的所有端口的SNMP数据,以及单方向Netflow数据。其中,SNMP数据中需要准确标记端口类型(up/down/peer),读取up端口的flow index,记录在Netflow中相同index的flow数据。
根据Ne tf low中的源IP、目的IP,比对BGP路由表中的AS信息;由AS号对应出不同区域,从而区分出区域流量分布;由AS号及用户的IP地址,区分出用户流量的分布;由AS号及业务的IP地址,区分出业务流量的分布。
以业务区域统一和业务区域不统一两种情况为例,通过进行区域流量分布分析和业务流量分布分析来说明采集和分析方法,如图7、图8所示。

图7 业务区域统一情况下的流量采集和分析

图8 业务区域不统一情况下的流量采集和分析
在区域流量分布分析时,方法为:(1)在绿色采集层获取IDC1、M A N1的所有端口S NM P、入方向Netf low数据;(2)根据SNMP端口表,得到所有UP端口的index;(3)在Netflow数据中获取匹配到index的所有数据;(4)根据Netflow数据中的源地址、目的地址查BGP路由表,打上区域标签。
这样,在区域流量分析时,IDC1(AS 1111)、IDC2(AS 2222)及MAN(AS 2222)的流量将被标记为区域A。两张图的区域分布相同。
在业务流量分布分析时,由于图8中IDC2为IDC业务,需要被标记为IDC而不是MAN,因此需要增加一步:源地址为2.2.2.2的IDC2流量,打上业务标签IDC。
这样,在做业务流量分析时,图7中IDC1(AS 1111)、IDC2(AS 1111)的流量被标记为IDC业务,而图8中IDC1(AS 1111)、IDC2(AS 2222)的流量被标记为IDC业务。在实际生产过程中,这种情况非常普遍。
流量校准机制
为确保数据准确完整,可将SNMP数据与Netflow数据作为两个数据源,进行比对,互相校准。如以天为颗粒度,取各区域核心设备上行出口Netflow分析数据与设备上行出口电路SNMP数据进行比对,出现偏差立即核准。
数据库选择考量
为实现互联网流量分布计算,可采用图9的数据库架构。来自网络的Ne tf low流量数据,先传输到消息中间件Kafka中。这是因为Netflow流量数据非常大,大数据分析过程中瞬时间产生大量数据,使用Kafka作为缓冲,可将不能及时处理的数据存入Kafka中队列等待。

图9 可实现互联网流量分布计算的数据库架构
对K af ka流量进行RNN模型训练,即流量预测、监控、端口误差分析,同时使用Flink对Kaf ka流量进行分析计算。Flink具有低延迟、容错强的特点,同时Flink有一个时间水位机制,可以限定晚到达的数据同样能够统计到同一时间点中。
然后将结果输出到Clickhoue分布式数据库中存入中间表,保证大量的数据存储查询性能不受影响,同时满足各种分析、多种内置函数使用,在大量数据查询时稳定高效。最终输出分析结果。
互联网流量分布计算模型应用及效果
骨干核心采集模型精细化程度不足,只能进行区域间的流量分布计算,不能细化到业务。因此,目前采用区域核心采集模型,在区域核心层部署采集,基本达到了预期的效果。
实际采集量
1. 设备量
在实际应用中,区域边缘设备采集近1000台,上下联电路数量大约20万条。利用这些设备和电路做全量采集。
2. 数据量
根据上述分析,对SNMP和Netflow数据进行采集。其中SNMP数据量每天大约50MB,Netflow数据每天120TB,其采样比为3000:1。
应用及效果
1. 区域分析
通过区域数据,可以得到区域—区域间总流量视图、某区域—其他区域流量视图,如图10所示,从而全面掌握区域间的流量分布。

2. 用户分析
根据用户信息,可以得到某用户—区域的流量分布,从而掌握用户在各区域间的流量分布和调度情况。
3. 业务分析
根据业务信息,可以得到某业务—区域的流量分布,掌握业务流量在各区域间的分布。尤其是针对同质业务,此类分析将有助于分析业务分布的合理性。
4. 趋势分析
根据历史积累的数据得出多维度的流量变化规律,从而辅助预测和判断整体、区域间、单区域、用户、业务流量的变化,如图11所示,为调节区域间、用户间、业务间流量分布提供较为可靠的量化数据依据。

